
Ending. Translation of the first part
I'm not worried about jobs. Or deepfakes. Or obscene words that the language model may use when communicating on the Internet. What really worries me is that humanity has come close to creating an entity that will be smarter than us. The last time this happened was when early hominids appeared, and it didn't end well for their competitors.
The basic argument was presented by Nick Bostrom in his 2003 book Superintelligence. It examines a thought experiment about the production of paper clips. Let's say a superhuman AGI tries to improve such production. He will probably first improve the production processes at the paperclip factory. When he maximizes the factory's capabilities, turning it into an optimization miracle, the creators of AGI will consider the job done.
However, AGI will then discover there other ways to increase the production of paper clips in the universe – after all, this is the only task assigned to it. To solve it, he will begin to accumulate resources and power. This is called instrumental convergence: almost any goal is easier to achieve through increasing power and access to resources.
Since AGI is smarter than humans, it will accumulate resources in ways that are not obvious to us. After several iterations, AGI will come to the conclusion that it can produce many more paper clips if it gains complete control over the planet's resources. Since people will stand in his way, he will have to deal with them first. Soon the entire Earth will be covered with two types of factories: those producing paper clips and those assembling spaceships for expansion to other planets. This is the logical progression for any optimizing AGI.
Paper clips are just an example. At first glance, the situation seems rather stupid: why would AGI engage in such nonsense? Why would we program an AI with such a ridiculous task? There are several reasons for this:
– Firstly, we do not know how to set a goal in the context of all our values, since they are too complex to formalize. People can only formulate very simple problems. And we mathematicians know that functions are often optimized for extreme values of their arguments.
– Secondly, the problem of instrumental convergence: for the implementation of any goal (even the production of paper clips!) it will always be beneficial to gain power, and resources, ensure one’s own security, and, probably, increase one’s level of competence, in particular, become wiser.
– Thirdly, the thesis of orthogonality: the task set and the level of intelligence used to achieve it are orthogonal, that is, they do not correlate; superintelligence may pursue rather random goals, such as maximizing the production of paper clips or making everyone smile and say nice things. I'll leave the more monstrous options to your imagination.
These reasons by themselves do not predict a specific disaster scenario, and discussing possible options is rather pointless. Our example with paper clips looks rather far-fetched. But a combination of reasons suggests that AGI, when and if it arrives, could quickly take the world by storm. Eliezer Yudkowsky, whose warnings have been especially loud lately, comes to this conclusion through the example of a chess game. If I sit down to play against a modern chess program, no one can accurately predict the moves in our game, what kind of opening we will play, and so on – the number of possible paths is incredibly large. However, predicting the end result – the victory of the program – is easier than ever.
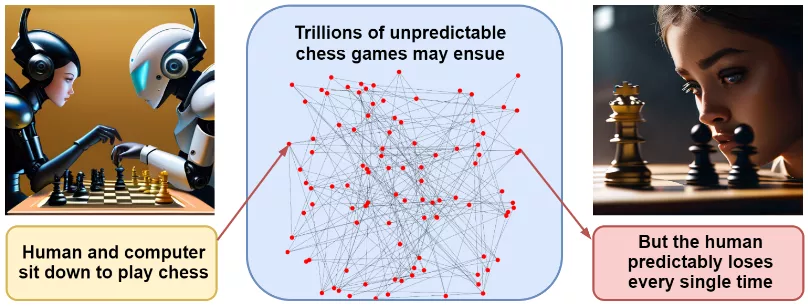
In the same way, one can paint a million disaster scenarios associated with the development of superintelligent AI. Each of them individually is unlikely, but they all end the same way – with the victory of the smarter AI, always focused on obtaining maximum power.
But won't people notice that the AI is out of control and turn it off? Let's continue our analogy. Think about a chimpanzee, in whose eyes a man made a certain instrument out of a wooden stick and string. Will a chimpanzee realize that a bow pointed at him means death before it's too late? How can we hope to understand anything about AGI when it is infinitely smarter than us?
If all this still does not convince you, let’s go through the standard counter arguments.
First, so what if AI reaches human or superhuman levels? Albert Einstein was very smart, studied nuclear physics, and did not destroy the world.
Unfortunately, there is no law of physics or biology that proves that human intelligence is close to the cognitive limit. Our brain size is limited by energy consumption and complications during childbirth. In cognitive tasks that do not rely solely on human experience to learn, such as chess and Go, AI has left us far behind.
Okay, the AI can become very smart and cunning, but it's locked inside a computer, right? We just won't let him get out!
Alas, we are already allowing it to “go out”: people willingly give AutoGPT access to their personal mail, the Internet, personal computers, and so on. AI with access to the Internet will be able to persuade people to perform seemingly innocent actions – print something on a 3D printer, synthesize bacteria in the laboratory from a DNA chain... with the current development of technology, there are infinitely many such possibilities.
The next argument is: okay, you and I seem to be at a dead end, but has humanity somehow managed so far? But people have invented many dangerous technologies, including the atomic and hydrogen bombs.
Yes, people are good at science, but their first steps in control often turn out to be unsuccessful. Henri Becquerel and Marie Curie died due to exposure to radiation. Chernobyl and Fukushima exploded despite our best efforts to ensure nuclear safety. "Challenger" and "Columbia" exploded in flight... And with AGI there may not be a second chance – the damage may be too great.
But if we don't know how to curb AGI, why not just stop developing it? No one is claiming that GPT-4 is destroying civilization, and this technology has already become a breakthrough in many areas. Let's stick with GPT-4 or GPT-5!
The solution is excellent, but it’s not clear how to implement it. It's unclear how long Moore's Law will last, but today's gaming graphics cards are nearly on par with the performance of industrial clusters just a few years ago. If several video cards in the garage are all you need to run AGI, it will be impossible to control this. Stopping the development of computer hardware is an option, but coordination will require the cooperation of all countries without exceptions, such tempting exceptions to accelerate the development of the economy or military technologies... Our attempts to protect ourselves are quickly becoming much more far-fetched than in the story with paper clips. It is very likely that humanity will continue to happily create more and more powerful AIs one after another until the very end.
Gloomy, isn't it?

What we can do? What are we doing?
The AI community is working in several directions:
– study of interpretability; we try to understand what's going on inside large AI models, hoping that understanding will lead us to control;
– AI safety; usually in relation to fine-tuning large language or other models using reinforcement learning based on human feedback (RLHF, reinforcement learning with human feedback);
– AI alignment; alignment of AI values with human values, which aims to teach AI to “understand” and “cherish” human values, limiting the unbridled expansion of paper clip production. Creating AI translators could help, but it is a difficult task and the results so far have not been impressive. Modern large language models work like a black box – almost the same as the human brain: we understand well the work of an individual neuron. We know which part of the brain is responsible for speech, and which is for motor function, but we are terribly far from the ability to read minds.
Improving AI safety through RLHF (Reinforcement learning from human feedback) and other similar technologies may seem more promising. Once found, jailbreaks can be successfully patched. However, who can guarantee that this is not a useless cosmetic repair? The concern is illustrated by a popular meme in which researchers gave Shoggoth (a monster created by Lovecraft) a cute emoji.
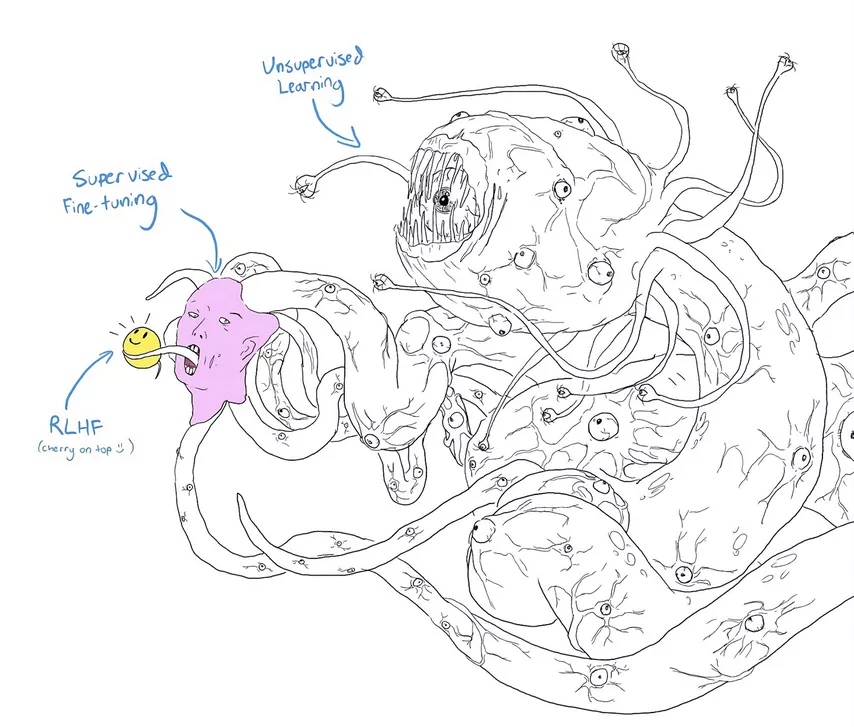
Most of all, I would like to teach potential AGIs to take our values into account and care about us. The problem can be divided into two parts:
– external alignment is trying to learn how to translate our values into a language understandable to AI models; If we design an objective function, will we be happy when it actually turns out to be optimized? How to even develop it? The problem with the paperclip example falls into this category.
– internal alignment is the problem of how to make the model actually optimize the objective function that we develop for it; This may seem like a tautology, but it is not: for example, it is quite possible that the goals that arise during model training coincide with the goals on the training set, but will diverge catastrophically when they are applied “free-floating”.
Unfortunately, today we have no idea how to solve these problems. There are many examples of unsuccessful alignment in game examples, when the model begins to optimize the objective function we formulated but comes to unexpected and undesirable results.
One of the interesting concepts associated with work in the field of internal alignment is called the Waluigi effect – the evil antipode of Luigi from the Nintendo series of games about Mario. Let's say we want to train a large language model (or other AI model) to perform some desired behavior, such as being polite to people. There are two ways to achieve this:
– really become polite (Luigi);
– pretend to be polite while being hostile to people (Waluigi).
The paradox is that choosing the second path turns out to be much more likely! External manifestations will be indistinguishable, but Luigi is an unstable balance, and any deviation from it at a distance irreversibly leads to Waluigi being a double agent.
Moreover, to turn Luigi into Waluigi, it is enough, roughly speaking, to change one bit – the plus sign to the minus sign. It is much easier (say, from the perspective of Kolmogorov complexity) to define something when you have already defined its exact opposite.
I mentioned only two problems related to alignment. A much more complete list can be found in Yudkowsky's article AGI Ruin: A List of Lethalities. Yudkowsky is one of the main heralds of the AI apocalypse, and his argument seems quite convincing.
What should we do? Most researchers believe that sooner or later we will have to take the problem of alignment seriously, and the best thing to do now is to pause the development of AI until real progress is made in controlling it. This line of argument, reinforced by the explosive development of AI in the spring of 2023, has already generated serious discussions at the state level about the regulation of AI.
Here's how it happened (all quotes are correct):

March 30, 2023
– One expert... says that if the development of AI is not frozen, “literally all people on Earth will die.”
(Laughter in the press box)
– Peter, well, you say, too...
May 30, 2023
– A group of experts claims that AI threatens the existence of humanity to the same extent as nuclear war and pandemic.
(Silence)
– AI is one of the most powerful technologies of our time. We must mitigate the risk... We invited the CEO to the White House... Companies must behave responsibly.
The existential risk associated with AGI entered public discourse this spring. Meetings at the White House, congressional hearings with key industry players including OpenAI CEO Sam Altman, Microsoft CEO Satya Nadella, Google and Alphabet CEO Sundar Pichai. Industry leaders have confirmed that they take these risks seriously and are prepared to exercise caution as they improve AI.
An open letter warning about AGI that appeared in late May was signed by thousands of AI researchers. The text of the letter was laconic:

Reducing the risk of extinction due to AI should be a global priority, along with other planetary risks such as pandemics and nuclear war.
I'm sure it was difficult to find one sentence that everyone could agree on. However, this proposal certainly reflects the current mood of most participants. No real legal action has been taken yet, but I think that regulatory action is on the way, and, more importantly, the approach to developing AI capabilities will be revised to a more cautious one. Alas, we cannot know whether this will be enough.
Conclusion
I hope you weren't too excited about that last part. The science of AI safety is still in its infancy but requires maximum effort. To conclude this article, I would like to list the key people who are currently working on AI alignment and related topics, as well as the key resources that are available if you want to learn more about it:
– The main forum for discussion of all matters related to the dangers of AGI is LessWrong, a rationality-oriented portal where all the people listed below publish regularly;
– Eliezer Yudkowsky is a key figure; he's been warning us about the dangers of superintelligent AI for over a decade, and I can't help but recommend his magnum opus Sequences (which isn't just about AI), the aforementioned AGI Ruin: A List of Lethalities, AI Alignment: Why It Is Hard and Where to Start, his recent post Death with Dignity Strategy (please take this with a grain of salt), and of course the wonderful Harry Potter and the Methods of Rationality.
– Luke Muehlhauser is a researcher working on AI advocacy, particularly AI-related policy issues, at Open Philanthropy; For starters, I recommend his Intelligence Explosion FAQ and Intelligence Explosion: Evidence and Import.
– Paul Christiano is an AI alignment researcher who split from OpenAI to start his own non-profit research center; For a good introduction to this area, take a look at his talk Current Work in AI Alignment.
– Scott Alexander is not a computer scientist, but his Superintelligence FAQ is a great introduction to AI alignment and does a good job of explaining why his blog Astralcodexten (formerly known as Slatestarcodex) is one of my favorites.
– If you prefer to listen, Eliezer Yudkowsky has been appearing on a number of podcasts lately, where he lays out his position in detail. I recommend the 4-hour interview with Dwarkesh Patel (time flies!), EconTalk with Russ Roberts, and Bankless with David Hoffman and Ryan Sean Adams. The latter is especially interesting because the hosts clearly wanted to talk about cryptocurrencies and perhaps the economic effects of AI, but they had to face an existential risk and respond to it in real-time (they did a great job of addressing this in my opinion seriously).
– Finally, I've been following the AI spring mostly through the eyes of Zvi Movshovitz, who published weekly newsletters on his blog; There are already more than 30 of them, and I also recommend his other works on the blog and on LessWrong.
And with this long, but hopefully informative article, I conclude the entire series of articles on generative artificial intelligence. It was great to be able to talk about some of the most exciting developments in imaging over the past few years. See you again!
Sergey Nikolenko